AI声乐教师的产品思考
音频生成和音频理解是两个完全反向的领域。音频生成是生成式AI,音频理解是判别式AI。它们的逻辑是相反的。
一个声乐教师类产品他需要什么?
- 它需要它能听出用户声音的问题
- 它需要能给出围绕用户的建议
好的教师会怎么做?
好的声乐教师最好有从零到一的过程,他的天赋可能并不出众,但是他经过系统的训练可以达到专业的水平。他的理论要足够扎实,他的表达要足够精炼、形象化。他的教学要因人而异,耳朵要足够敏锐。
现在,我们思考AI是否能达到职业声乐教师的水平。
第一个核心问题:AI能否听出用户的问题
AI他需要识别用户的挤嗓、气虚等等问题,这些问题人来做的话会很快识别出来。有经验的教师会在一瞬间反应出学员的问题,并给出建议。这个过程就是经验。
如果用AI替代声乐教师的话,就要将经验的东西变成数据,然后通过AI去学习。幸运的是,经验相关的东西是可以被AI学习和理解的。强化学习非常适合这个场景。理论上只要有足够多的数据,AI可以学习到任何经验。像AI在围棋、dota等领域已经远远超过了人类。
第二个问题:AI能否给出围绕用户的建议
AI需要对用户的基础能力有一个大概的判断,比如真声音域、假声音域,基础水平等等。并且针对用户的问题,给出个性化的建议。这些建议要一针见血,要能够立刻见效。另外他需要对人类的身体构造有足够的了解,比如声带、喉咙、肺部、气息、发声位置等等。通过经验化的方法帮助用户找到好的发声方式。
更简单点说,他需要知道什么是好的,什么是不好的。他需要能设想出用户在当前天赋的情况下能达到的最好效果。(比如用户只能唱到F3,你让他唱到C5,那就是耍流氓)。并且有一个长期的规划和渐进式的反馈。
所以整体来看,这类产品是可行的,是能达到职业声乐教师水平的。
我们专注在第一个问题上,也就是AI能否听出用户的问题。这是一个判别式AI的方式,目前有几个开源研究可供参考。
Qwen2-Audio
我认为这是阿里开发的“力大砖飞”的模型,总参数为8.2B。它的原理也很简单:它会将音频通过Audio Encoder向量化,也就是将模拟信号转变成机器能看的懂的信息,再用其内置了一个QwenLM模型同时处理向量化的音频信号和输入的文本,通过SFT( 指令微调)和DPO(直接偏好优化)进行三重训练:预训练 → 指令微调(SFT) → 直接偏好优化(DPO),这里的DPO取代了强化学习步骤,通过人类偏好数据让模型自主反馈,并实现好的效果。
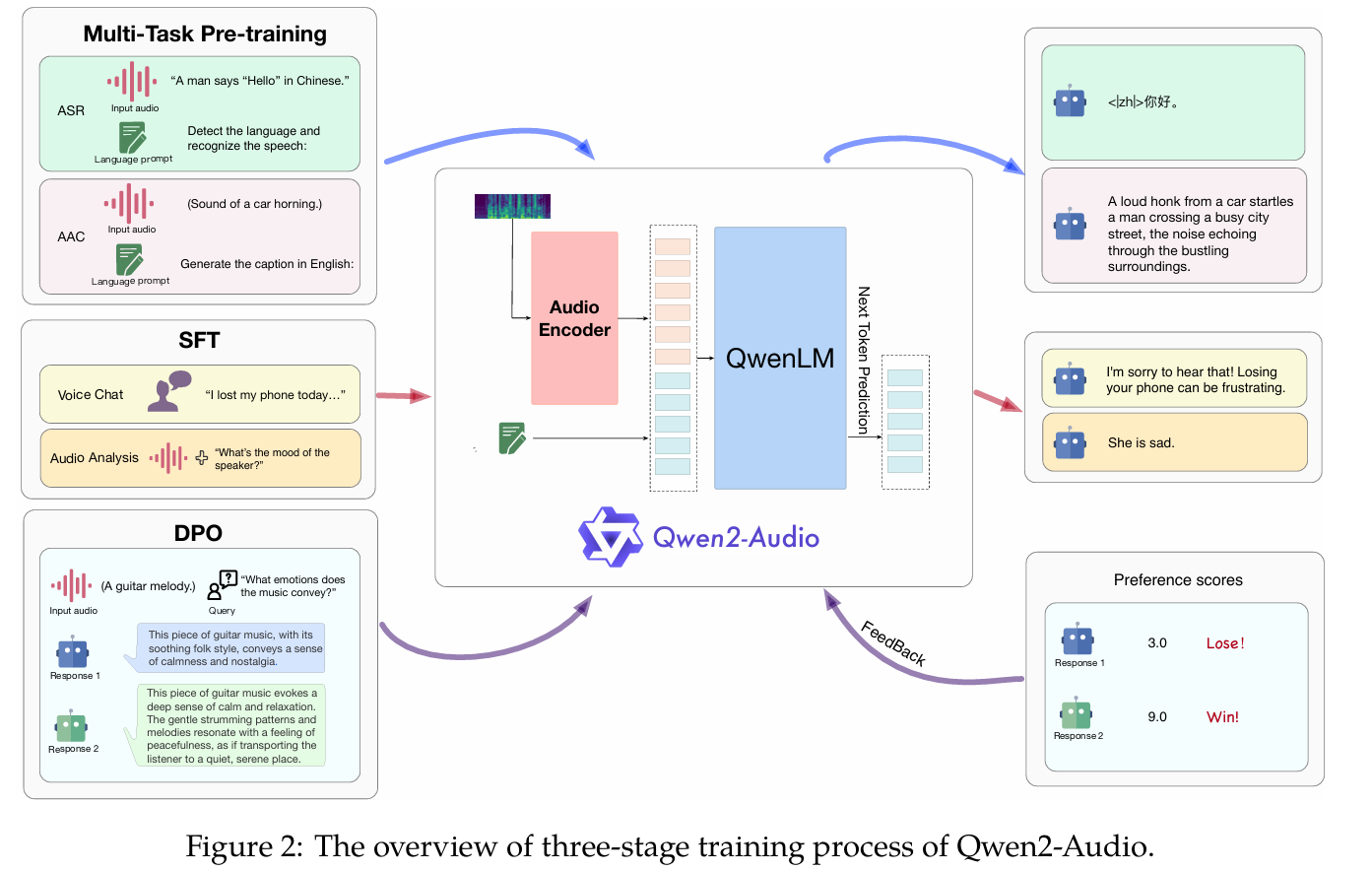
所以本质上它也是自回归预测的模型,它的回复模式与LLM非常像,那我们不禁可以畅想:LLM已经证明了它可以通过scaling的方式提升能力,那理论上音频模型也可以通过大量数据训练实现非常惊艳的效果,也就是Aha moment。
我们可以主要看下它的技术实现:
用Whisper-large-v3将输入音频预处理为128通道的Mel频谱图(16kHz采样率,25ms窗口,10ms步长)
语言模型采用Qwen-7B(70亿参数)
预训练采用了370K小时的演讲音频,10K的声音音频,140K歌曲音频。这可以在他的[文章]中看到。(https://arxiv.org/abs/2407.10759)
我看了下Qwen2-Audio使用的音频,基本全部是开源音频,质量都比较一般。对比suno的音频时长你会觉得还远远不够多,当然suno的数据是人们猜测的大小,我在上一篇文章讨论过它,它的数据量不会少。
Qwen2-Audio的模型效果也一般,无法与当前商用的相媲美,但是它提供了一个很好的思路,就是通过LLM去蒸馏一个音频模型。也算是证明了一个范式。
如果我做一个产品,我要训练一个音频模型,我会采用它的方式,因为它的方式贴近于人类的文字处理方式,人类就是通过文字传递知识,通过声音承载文字,所以音频和文字是相通的。我的产品设计哲学就是:AI尽可能贴近人类,人类的发展路线可能是大自然亿万年的最优解。。
这个模型可以直接进行语音交互,同时它可以为很多音频数据集提供数据标注,YUE的模型的很多数据就是用Qwen2-Audio标注的。
日本一个研究
Yuya Yamamoto 等(筑波⼤学/KAIST)在 ISMIR 2022 提出了J-POP演唱技巧分析 。他们构建了包含流⾏歌曲中13类演唱技巧标注的新数据集,并⽤机器学习模型检测歌曲中颤⾳、滑⾳(scoop/bend)、假声(falsetto)、喘息、嘶吼等技巧的出现 。
但它本身是CNN,不是LLM,所以它不能进行语音交互。只能识别特定的声乐技巧,没法规模化,也不符合我的产品设计哲学。我有考虑过用他的方法做一个DEMO,做了一天的数据集,但是最终还是放弃了,它不是这类产品的正确方案,没必要浪费时间。
传统强化学习的尝试
CNN+强化学习法
我做了一些传统强化学习的尝试,期待使用日本的这个研究,它只能检测几种声乐技巧,但它的模型数据够小,是可以做的到的。比如我们做了一个Excel ,将一些主流歌手的假声部分提取出来,甚至标注出了一句话中的假声的开始和结束。这是很废人的工作,我们做完了一些歌手的假声数据,但是放弃了。放弃的原因是我觉得在用最笨的方法做新奇的事情,简单的强化学习模型和基于LLM的音频模型在底层原理上是完全不同的,即便我的强化学习模型表现很好,也不能证明我们能用LLM去做我们想做的产品。我们不能拿它去忽悠消费者忽悠投资人。只能等待有更好的机会可以尝试做这个产品。
生成式AI做音频比对
另外我还尝试了另一种音频比较方法,用的是生成式AI 。这个解决办法比较有意思了:将我的声音克隆,然后把我的声音套到林俊杰的原声上,这样就像是大师在用我的嗓子来唱歌。我可以听到在我的天赋限制下,我可能达到的最好效果。
至于产品就更简单了,让AI 录入我的音色,我试过10S的音频效果就很好了,然后我再唱一首歌(比如林俊杰的等黑夜问白天),它将它生成的理论上我能唱的最好的音频与我实际的音频去比对,他就能发现我的问题。
这种比对效果通过MFCC等频谱特征可以实现,但是他还是不能智能的教我怎么做,他还需要提前录入音频,不过这个东西倒是测量歌曲音准的好方法,它也可以将我理论上最好的声音告诉我,让我知道应该怎么样去模仿最好的自己。不过在一些歌曲上,比如林俊杰的等黑夜问白天,林是真声,但是我是假声,听起来就会比较奇怪,我也无法达到他那样的通透感和声音效果,所以这个方法还是不能解决我的问题。
我可以之后单独发一个帖子比对目前生成式AI的音频克隆效果,这里就不赘述了。
总结
我觉得最好的产品是跟模型结合的,并且AI声乐领域是绝对的空白,而AI在声乐上的表现绝对会超出很多人的想象。它的技术并不复杂(在LLM突破后),它的原理是可行的。
如果问我为什么这么相信AI在声乐上的表现,我会说:直觉
我觉得产品经理的直觉是非常重要的,而且我的理论依据来自我的设计哲学:AI尽可能贴近人类,人类的发展路线可能是大自然亿万年的最优解。
有很多人不会识字但它可以说话、唱歌,所以文字和声音是可以不同编码的,但是它们的复杂程度是相近的,一个与人脑算力相近的AI就可以学会人类的声音处理。这也是为什么声音克隆发展如此迅速。而很多AI创业者都在关注生成式AI的音乐,我反倒觉得音频理解才是AI声乐领域最应该发展的方向。
AI生成音乐可以供人享受,而AI音乐分析可以供人进步,它是更容易有产品感的领域。
这种产品感的东西是研究人员做不出来的,而恰好很多研究人员会做这类研究,但他们对数据并不考究,经常使用糟糕的数据集,这就是AI创业者的潜在的机会。
to be continued..


