

伟大不能被计划
伟大不能被计划的含义到底是什么为什么伟大不能被计划?这是一本很发人深省的书,里面很多内容源自一名人工智能科学家、OpenAI 研究员:肯尼斯·斯坦利(Kenneth...
企业SAAS产品思考
ServiceNow SAAS现状公司的SAAS服务主要是将IT服务管理、人力资源管理、IT资产管理、财务运营管理等业务进行封装,提供给客户使用。为客户提供标准化管理和运营服务,帮助客户提升效率,降低成本。 中国的SAAS企业并没有像美国一样蓬勃发展但长期的历史以来,中国的SAAS企业并没有像美国一样蓬勃发展,也没有诞生出像ServiceNow、salesforce这样的独角兽企业。我觉得有很多原因:1、在中国大的企业往往不会选择SAAS,因为在中国,大企业往往更愿意自己开发,或者选择成熟度更高的产品,并且中国是一个人情社会,职业经理人的缺失让企业很难数字化转型。中国的SAAS创业公司成了传统企业转型的工具,扮演更多顾问和咨询的角色。2、中美的社会分工成熟度有一些差异,而且美国是全球资金的汇聚之地,这也是SAAS在美国能做起来的原因,其实SAAS一直是一个好生意:可复利、低风险、低预算。3、有人说SAAS是做标准...

AI旅游类产品思考
基础赛道分析我之前看一个分类,是VC那边的通用分类,AI的产品可以分为消耗时间的和节约时间的,可以分为B端和C端的,节约时间的C端产品往往会巨头林立,像这种方向往往是天使轮VC不会投的。 所以AI旅游类产品往往竞争激烈,它本身还是工具类,工具的目的是帮助用户完成任务,所以它需要引导用户,需要用户参与,需要用户分享。需要用户的认可,产生网络效应。但也是有一些例外的,比如Cursor,在主赛道上一个创业公司能先拔头筹,只能说在AI时代,一个小的团队也能有大的机会。只要更快一些,对AI的认知更深刻一些,是可以在主赛道上建立领先的。另外,如果一个创业公司 在主赛道上创造了惊人的价值,它是可以有很高的溢价被收购的。那对整个团队来说也是值得庆祝的事情。 国内赛道现状在国内,通用的、大赛道上的应用,大厂拥有绝对的流量优势、成本优势和资金弹药优势。这个问题其实创业者们已经面对和讨论过很多次了。Fundamentally,不要在他们的主航道上,也不要去做那些过于通用、实现方式比较直接(straight...
好的AI产品分析 1/100 Cursor
在这个专栏,我会用最简单的语言介绍我狂热喜爱的AI产品。也算是一个产品经理的自我提高和反馈的专栏。 Cursor我本身是Cursor的忠实用户,我在很早期就使用Cursor,当时的整体体验比较一般,也是接入了claude-3.5-sonnet,才会让代码生成质量产生质变。 有人会觉得不如把代码转发到Chatgpt里,OPENAI本身也支持多个文档,在当时看效果相似。但我觉得产品设计是多维度的,Cursor的体验更像是和AI一起编程,而不是一个代码转发的工具。 把代码转发再放到Vscode里是一种背离产品的过程,你无法控制幻觉和代码质量。 专业的事交给专业的人。专业的事也要交给专业的产品来做,尤其是代码编辑这样一个非常专业化的领域。想用一个泛化的界面解决所有问题,是不可能的。 产品简介Cursor 是一款近年来迅速崛起的 AI 驱动代码编辑器,被誉为增长最快的开发者工具之一。 与传统的插件式 AI 编程助手不同,Cursor 由 Anysphere 公司打造为“AI 原生 (AI-native)”的完整 IDE 环境,以深度融合人工智能来提升编程效率。 其创始团队(MIT...
Manus的多Agent架构怎么做?
在本文主要讨论两个问题:1、像Manus这样的多Agent系统,可以有哪些实现方式2、多Agent系统中,如何实现信息的管理和共享 我在用LangGraph开发一个多Agent系统,LangGraph基于Langchain开发,是一个基于图的控制流框架,它可以更好的实现动态循环调用工作流。 LangChain的优点我们就不赘述,可以说是早期的完善的对开发者非常友好的框架。但LangGraph的控制流是静态的,它需要预先定义好所有可能的节点和边。而我们用的所有的AI产品都希望可以动态执行工作流,这就是我们的核心问题:如何用LangGraph实现动态控制流? OpenAI 目前尚未公开其应用产品中多智能体(multi-agent)系统的具体架构细节(例如 ChatGPT 内部是否使用多个 Agent、是否使用静态图 LangGraph 或动态控制流等),但我们可以从 已公开的系统设计模式、相关研究趋势,以及 OpenAI 生态中类似产品(如 Manuscripts、AutoGPT、LangGraph 等)来合理推测其可能的实现方式。以下是系统性回答: 多 Agent...
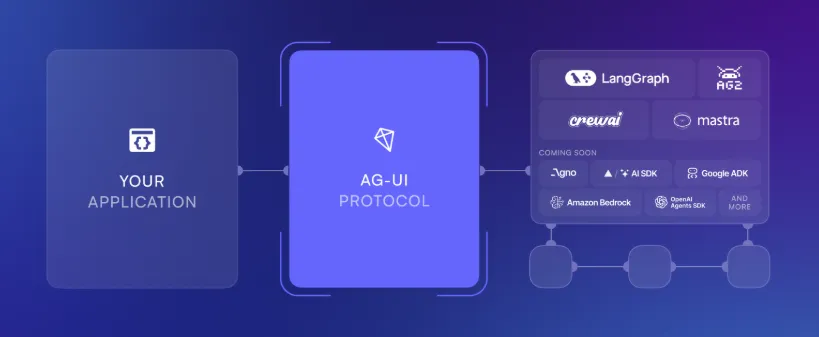
AG-UI使用指南
人们说MCP的下一步时AG-UI,那么AG-UI到底是什么呢?其实看他的定义就知道,代理+前端。我最近开发时应用时发现Cursor对前端的支持很糟糕,我需要新的工具和方法!! 以下是一些AG-UI的尝试,希望能帮助我解决这一难题。 什么是AG-UIAG-UI(Agent-User Interaction Protocol)的开源协议由CopilotKit提供,你可以把它想象成一套“通用语言”,专门用来解决AI代理和前端应用之间的沟通难题。 简单来说,AG-UI就像是在AI代理和你的App界面之间搭了一座“鹊桥”!我喜欢这个想法,不管它好用与否,他就是我需要的。https://docs.agentwire.io/introduction...

猫咪呼噜算法解析
几个月前我在做AI硬件产品,做了一个猫咪样子的AI陪伴式玩具的DEMO。它的核心功能之一就是猫咪的呼噜声,如果呼噜可以伴随它的心情和情绪而变化,他就会给用户更真实的体验。 有个印度裔开发者在十几年前做了个有趣的前端,https://purrli.com/...
Langgraph的持久化管理-记忆模块
持久化就是记忆,就是能让AI记住用户的定制化的核心。 LangGraph 有一个内置的持久层,通过校验指针实现。使用校验指针编译图形时,校验指针会在每个超级步骤superstep中保存图形状态的校验点checkpoint。这些检查点被保存到一个线程中,在图形执行后可以访问该线程。由于线程允许在图形执行后访问图形的状态,因此包括人在回路、内存、时间旅行和容错在内的多种强大功能都成为可能。有关如何在图形中添加和使用定点器的端到端示例,请参阅本指南。下面,我们将详细讨论这些概念。 这个checkpoint的概念非常重要,需要详细理解。 checkpoint检查点是在每个超级步骤中保存的图形状态快照,由具有以下关键属性的 StateSnapshot 对象表示:config: Config associated with this checkpoint.metadata: 与该检查点相关的元数据。values: 此时状态通道的值。next 图中下一个要执行的节点名称元组。tasks:PregelTask...

Langgraph的魅力
作为一名AI产品经理,Langgraph的魅力在于它提供了一种新的方式来构建AI应用。他用轮询的方式构建应用,我觉得比传统的Agent更符合直觉。https://github.langchain.ac.cn/langgraph/...