如何构建一个唱歌模型
事实上,我并没有成功的做出一个AI音频模型,以上只是我作为一名连续创业者的思考和尝试,供大家思考。我一直在关注Idoubi的开发成果和产品哲学,他有一个AI音乐播放器产品Melodisco我很喜欢,但是据他所述,AI生成的曲风单调,并且他没有自己的音乐模型,仅从产品体验层面无法赶超Suno / Udio 这些模型厂,而且目前的好的音频模型全部是闭源的,让很多创业公司望而却步。
作为音乐爱好者,我不禁思考实现音频模型的难度,我想知道基于一个LLM模型去蒸馏一个音频模型的可行性。以下是一些思考的内容,供大家参考。
音频生成模型研究
开源模型
GPT-SOVITS
GPT-SoVITS是花儿不哭大佬研发的低成本AI音色克隆软件,我仔细的看了大佬的训练方式,只能说在算法上做到了极致,将训练成本降到了很低的地步,非常适合个人使用。它的AI tts功能堪称惊艳,几秒钟可以克隆我的音色。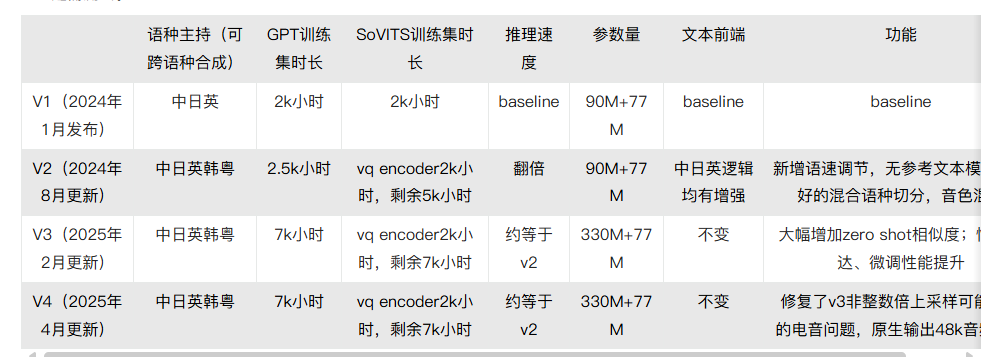
GPT-SoVITS的核心架构包含两个主要部分:
- 文本到语义(Text-to-Semantic):使用GPT模型将文本转换为语义表示
- 语义到声音(Semantic-to-Voice):使用SoVITS模型将语义表示转换为目标音色的声音
这个模型在声音处理上效果很好,但是在声乐处理上表现一般,它至今没有推出声乐处理功能。但是它给了我们一个很重要的启示,就是音色是很容易被克隆的,声乐应该也是如此。
Cosy-voice2
https://github.com/FunAudioLLM/CosyVoice
cosy-voice2是基于LLM的音频生成模型,它通过LLM将文本转换为音频,然后通过SoVITS模型将音频转换为目标音色的声音。
Cosy-voice2主要是语音合成,不支持声乐处理,它用了200000小时的数据集来训练语音标记符,它的TTS效果是我认为在开源模型中最好的。
并且应用的稳定性,生成速度都达到了商用级别,我可以随意建立一个网站,租用服务器专门开设这样一个音频生成服务,然后通过API提供给用户使用。但是它的门槛就比较低,偏工程化,也是我目前没有考虑的方向。
YUE
这是港科大团队搞得专门音频生成模型,开源的,完全对标suno。体验上与suno相比差了很多。但是整个方法和思路十分值得学习。它本质也是基于自回归语言模型的框架,这类产品有几个核心点:1、内置LLM基础模型,YUE引入的就是LLaMA2jiagou ,2、它的音频生成方式很像LLM输出文本的过程,所以长文本的输出能力是两者都非常重要的指标。3、独立生成音乐和声乐内容后拼接。
另外我要吐槽一下它使用的数据集,基本上是开源的,我听了一部分,给我听YUE了。数据集的质量实在是太差了,就像是一个完全业余的团队为了发文章让学生录制的音频。想训练一个合格的模型,算法+环境+数据集缺一不可。 算法经过了漫长的演化,已经诞生了无数优秀的算法。但环境和数据需要结合具体的应用,需要相关从业者结合AI的能力,去训练出符合应用场景的模型。
我们能看到基本所有的音频模型都会内置大语言模型,这是音频模型能脱颖而出的关键因素。
闭源模型
Udio
Udio 是另⼀款备受瞩⽬的AI⾳乐⽣成⼯具,由前DeepMind⼯程师创办的团队开发,于2024年初推出公测。我估计它的训练过程与MusicLM和Suno都类似
Suno
Suno的模型是闭源的,它也是目前我认为最优秀的音频模型。Suno官⽅未披露其训练数据的具体来源,甚至可以说严格保密。有社区讨论推测其训练集规模约150万⾸歌曲(涵盖不同语⾔,其中约⼀半为英语歌曲) ——这⼀规模与OpenAI早期的Jukebox模型相当 。虽然具体数字未经官⽅证实,但可以肯定Suno的训练数据量极为庞⼤,远超⼀般开放数据集的规模。
技术架构上Suno 找到了创新的解决方案:TTS 训练过程的主要限制是「text to speech」训练数据非常有限,所以 Mikey Shulman 他们另起炉灶,直接在 audio (音频) 数据上进行训练,然后 tweak (调整) 模型使其能执行文本到语音的任务。你可以理解为,他们将音频数据转换成了「tokens」,然后利用这些音频 tokens 进行自监督学习 (self-supervised learning) ,因此 Bark 学到了人类真实音频的各种特征和模式,能够端到端创作出令人震惊的、类似人类的音乐。
标注⽅式:Suno并未公布有没有对数据进⾏⼈⼯标注划分。但从其产品功能推测,高层标签(如流派、情绪、年代、乐器类型)应在训练时作为条件输⼊的⼀部分。这些标签可能来自原歌曲的分类(例如音乐平台上的风格标签),或者通过模型⾃动分类获得。鉴于歌曲结构标注需要逐段划分,这在百万级数据上难以人工完成,更可能的做法是模型⻓序列训练+位置嵌⼊的⽅式,让Transformer直接学习⻓程依赖,从而掌握常⻅的乐段⻓度和衔接⽅式。演唱技巧等更细粒度的信息(如歌⼿⾳⾊、唱法)没有证据表明有显式标签,模型⼤概是通过模仿数据中不同歌⼿的声音特质自⾏掌握的。
整体来看
Suno、Udio倾向“海量实例+弱标注”以追求逼真度。在标注精细程度上,MusicLM的MusicCaps提供了精细描述但规模小;MusicGen依赖现成标签中等精度;Suno和Udio基本无人工精细标注,靠模型自我学习结构和风格。如果数据够好,一定可以训练出非常惊艳的模型。
如何训练一个唱歌模型
回到我们最初的问题,如何训练一个唱歌模型。结合产品,我们希望这个模型可以生成多种风格的歌曲和声乐,通过内嵌LLM模型的方法,将音频向量化,进行分层语义建模。我们可以看下目前开源的多模态模型,VLM,视觉-语言模型,它将视觉和语言向量化,进行分层语义建模。声音-语言模型,将声音和语言向量化,进行分层语义建模。
所以从产品的角度,国内完全有实力诞生一个Suno,甚至超越它。我觉得Suno的模型,在技术上没有特别难的地方,难的是数据集的积累和标注。
在我看来音频还远远没有达到预训练的上限,它在生成表现上完全可以达到LLM的水平。语音一直以来作为承载信息的重要载体,它与文字的表达能力是等价的。甚至在产品方面它可以有更大的市场规模。
很难讲我们是先会说话还是先会写字,明明有很多文盲他们无法写字,但却能清楚的用语言表达自己的想法。也就是说,语音是比文字更基础的表达方式。它在大脑中的存储方式是模块化的,文字只是外化的表达。如果我们可以将AI的语音能力提升到与文字能力等价,那它也许更贴近人的思维表达。


